Structural Equation Modeling in R Tutorial 5: Exploratory Factor Analysis using psych in R
Table of Contents
Made for Jonathan Butner’s Structural Equation Modeling Class, Fall 2017, University of Utah. This handout begins by showing how to import a matrix into R. Then, we will overview how to determine number of factors, or dimensions, to extract from your data. Next, we will overview how to extract factors and perform a facor analysis without rotation. Finally, we’ll review a few rotation methods, specifically focusing on two types of rotation: orthogonal, which does not allow latent factors to correlate (correlations between latent factors are constrained at 0), and oblique, which allows latent factors to correlate. This syntax imports the 9 variable, 615 person dataset from datafile hbmpre1.txt. The dataset is from Leona Aiken and includes multiple items indicating women’s perceived susceptibility and severity of getting cancer. The first four items are believed to be indicators of susceptibility of getting cancer again, the last five items are believed to be indicators of severity of cancer.
Data Input
First, we will read in datafile using Fortran and clean up the datafile a little bit.
library(psych) #for doing exploratory factor analysis
library(GPArotation) #for doing rotation
# make sure to set your working directory to where the file
# is located, e.g. setwd('D:/Downloads/Handout 1 -
# Regression') you can do this in R Studio by going to the
# Session menu - 'Set Working Directory' - To Source File
# Location
efadat <- read.fortran("hbmpre1.txt", c("F5.0", "9F5.0"), na.strings = 99)
# note that we recode missing values! note: #The format for a
# field is of one of the following forms: rFl.d, rDl.d, rXl,
# rAl, rIl, where l is the number of columns, d is the number
# of decimal places, and r is the number of repeats. F and D
# are numeric formats, A is character, I is integer, and X
# indicates columns to be skipped. The repeat code r and
# decimal place code d are always optional. The length code l
# is required except for X formats when r is present.
efadat <- read.table("hbmpre1.txt", na.strings = 99) #this does the same thing as the read.fortran statement above
# add column names
names(efadat) <- c("id", "i1", "i2", "i3", "i4", "i5", "i6",
"i7", "i8", "i9")
efamat <- cor(efadat[, 2:10], use = "complete.obs") #make a correlation matrix, since many factor
# analysis functions in R only work on correlation matrices.
# use=comlete obs means that we implement listwise deletion
# of missing values note that we subset out the ID column of
# the dataset so that we dont make a correlation with ID.
# This code means to select all rows and only columns 2
# through 10 from the dataframe efadat.
Scree Plot and Parallel Analysis
One more traditional way to determine the number of factors to extract is to make a scree plot. This is probably the oldest and most “subjective” way of determining extraction, but still works if you have clean enough data. Here I’ll show that technique together with parallel analysis, since a single command will give you both. Parallel Analysis is arguably the preferred technique right now for determining number of factors to extract. Parallel Analysis essentially simulates data that is similar to yours but where there is less commonality between items. It then uses this simulated data to provide reasonable suggested cutoffs for your scree plot (that you would normally make just eyeballing the scree plot). It provides a more objective evaluation of the scree plot than the eye test.
fa.parallel(efamat, n.obs = 615) #parallel analysis
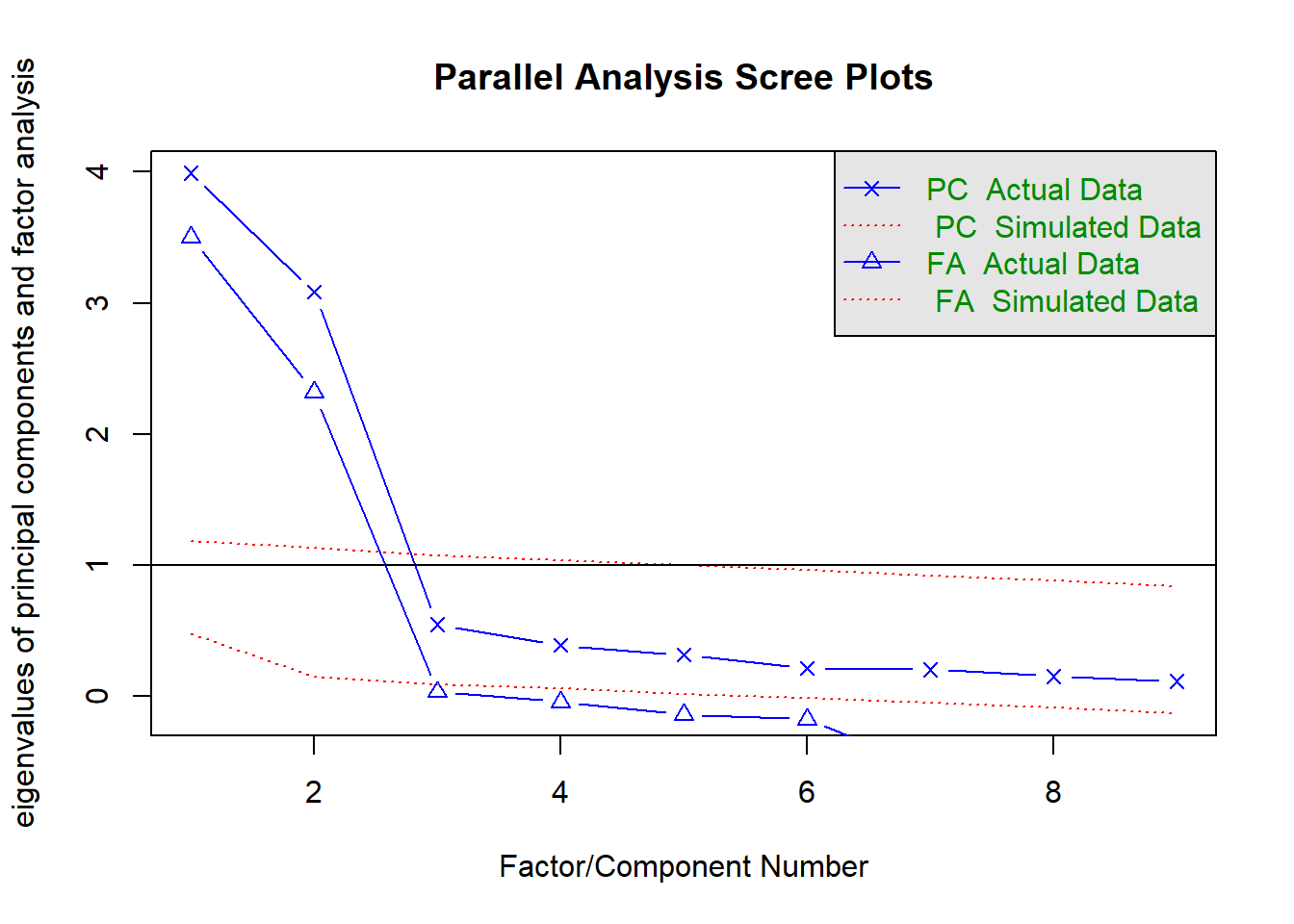
## Parallel analysis suggests that the number of factors = 2 and the number of components = 2
# n.obs is the number of people/rows in your dataset. Note
# that if you use a correlation matrix for any function, you
# will likely have to use the n.obs argument.
# if you wanted to manually build a scree plot, use the below
# code, which plots eigenvalues plot(eigen(efamat)$values)
In this output, the scree plot is represented by the blue line with triangles (labelled FA actual data). The parallel analysis here suggests extraction of 2 factors.
Minimum Average Partial
Another way to determine number of factors to extract is to use the minimum average partial (MAP). The minimum average partial is a method suggested by Velicer (1976). The vss function is from the psych package, and will plot fit for various factor fits to the data. In the plot provided, higher on the y axis is better. For the minimum average partial, you’re looking for the “The Velicer MAP achieves a minimum of 0.06 with 2 factors” part of the output. Lower numbers indicate better fit with the minimum average partial. Notice here that the minimum average partial result converges with the suggestion from parallel analysis, suggestng that 3 factors is likely the correct number to extract from your data.
vss(efamat, n.obs = 615, rotate = "varimax", diagonal = FALSE,
fm = "minres")
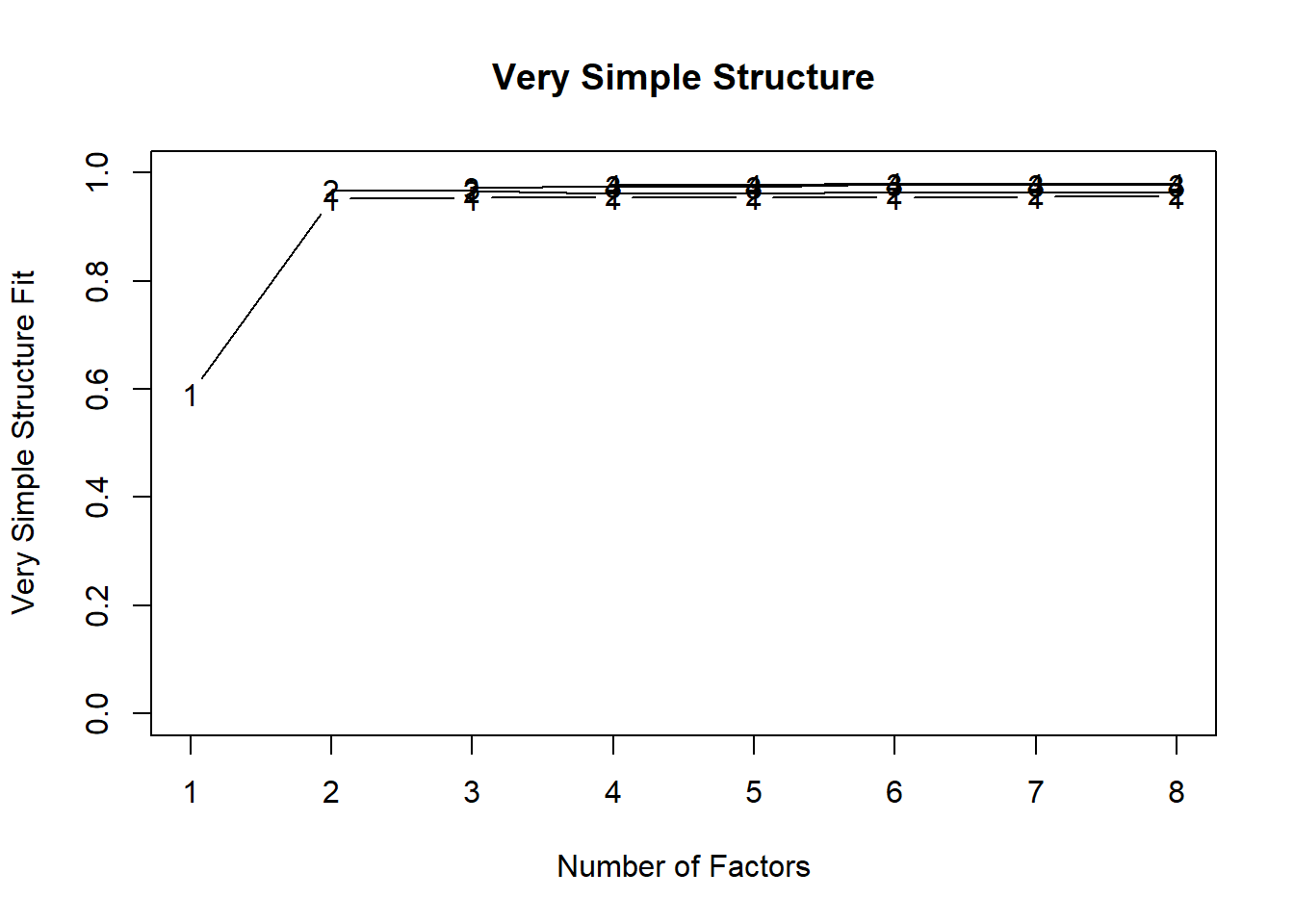
##
## Very Simple Structure
## Call: vss(x = efamat, rotate = "varimax", diagonal = FALSE, fm = "minres",
## n.obs = 615)
## VSS complexity 1 achieves a maximimum of 0.96 with 8 factors
## VSS complexity 2 achieves a maximimum of 0.97 with 2 factors
##
## The Velicer MAP achieves a minimum of 0.06 with 2 factors
## BIC achieves a minimum of NA with 4 factors
## Sample Size adjusted BIC achieves a minimum of NA with 4 factors
##
## Statistics by number of factors
## vss1 vss2 map dof chisq
## 1 0.59 0.00 0.302 27 2545.96735424035
## 2 0.95 0.97 0.055 19 242.88701918077
## 3 0.95 0.97 0.104 12 135.00034752069
## 4 0.95 0.96 0.145 6 15.95383264929
## 5 0.95 0.96 0.184 1 1.04211355050
## 6 0.96 0.97 0.310 -3 0.08177651495
## 7 0.96 0.96 0.525 -6 0.00000778140
## 8 0.96 0.96 1.000 -8 0.00000000036
## prob sqresid fit RMSEA BIC
## 1 0.000000000000000000000000000000000000000000 10.67 0.59 0.3913 2372.6
## 2 0.000000000000000000000000000000000000000085 0.83 0.97 0.1392 120.9
## 3 0.000000000000000000000060992517414400371049 0.71 0.97 0.1299 57.9
## 4 0.014003923251124768267761311335561913438141 0.60 0.98 0.0524 -22.6
## 5 0.307330424984205485827715165214613080024719 0.56 0.98 0.0094 -5.4
## 6 NA 0.48 0.98 NA NA
## 7 NA 0.51 0.98 NA NA
## 8 NA 0.51 0.98 NA NA
## SABIC complex eChisq SRMR eCRMS eBIC
## 1 2458.3 1.0 4155.151861911172 0.306330080 0.3537 3981.8
## 2 181.2 1.0 27.792660816548 0.025053088 0.0345 -94.2
## 3 96.0 1.1 13.552228335971 0.017494501 0.0303 -63.5
## 4 -3.5 1.1 1.158141103387 0.005114191 0.0125 -37.4
## 5 -2.2 1.2 0.046316592750 0.001022738 0.0061 -6.4
## 6 NA 1.2 0.003511638653 0.000281612 NA NA
## 7 NA 1.2 0.000000767729 0.000004164 NA NA
## 8 NA 1.2 0.000000000015 0.000000018 NA NA
Factor Extraction
A first method of factor extraction is referred to as Principal Components analysis, or PCA. Principal compoennts analysis differs from Principal axis factoring and other factor analysis techniques in that it assumes that there are no item-based errors, or residuals (the unique errors for each item are 0, all variance is a part of the true score latent variable).
components.norotate <- principal(efamat, nfactors = 2, rotate = "none") #principal components analysis
components.norotate #ask for loadings and variance accounted for
## Principal Components Analysis
## Call: principal(r = efamat, nfactors = 2, rotate = "none")
## Standardized loadings (pattern matrix) based upon correlation matrix
## PC1 PC2 h2 u2 com
## i1 0.52 0.73 0.81 0.19 1.8
## i2 0.58 0.71 0.84 0.16 1.9
## i3 0.56 0.73 0.84 0.16 1.9
## i4 0.56 0.75 0.88 0.12 1.9
## i5 0.75 -0.43 0.76 0.24 1.6
## i6 0.78 -0.45 0.81 0.19 1.6
## i7 0.63 -0.39 0.55 0.45 1.7
## i8 0.78 -0.49 0.85 0.15 1.7
## i9 0.77 -0.41 0.75 0.25 1.5
##
## PC1 PC2
## SS loadings 3.99 3.08
## Proportion Var 0.44 0.34
## Cumulative Var 0.44 0.79
## Proportion Explained 0.56 0.44
## Cumulative Proportion 0.56 1.00
##
## Mean item complexity = 1.7
## Test of the hypothesis that 2 components are sufficient.
##
## The root mean square of the residuals (RMSR) is 0.05
##
## Fit based upon off diagonal values = 0.99
Note how these two components alone account for 78% of the variance in our items! Before getting into rotation, I’ll review another factor extraction technique called principal axis factoring. Principal axis factoring is sometimes referred to as PAF in the literature. Principal axis factoring and other factor analysis techniques differ from principal compoennts analysis in that they assume item-based errors, or residuals. Note that there are several estimation methods that can be used to extract factors, only one of which I demonstrate here. See comments in the code for more on alternative estimation methods, such as maximum likelihood, which assumes multivariate normality.
factor.2.norotate <- fa(efamat, nfactors = 2, n.obs = 615, rotate = "none",
fm = "pa")
factor.2.norotate #per variable loadings for 3 factors, unrotated solution
## Factor Analysis using method = pa
## Call: fa(r = efamat, nfactors = 2, n.obs = 615, rotate = "none", fm = "pa")
## Standardized loadings (pattern matrix) based upon correlation matrix
## PA1 PA2 h2 u2 com
## i1 0.52 0.67 0.72 0.28 1.9
## i2 0.59 0.66 0.79 0.21 2.0
## i3 0.57 0.68 0.79 0.21 1.9
## i4 0.59 0.71 0.86 0.14 1.9
## i5 0.71 -0.44 0.69 0.31 1.7
## i6 0.74 -0.47 0.77 0.23 1.7
## i7 0.54 -0.36 0.42 0.58 1.7
## i8 0.76 -0.52 0.85 0.15 1.8
## i9 0.72 -0.42 0.69 0.31 1.6
##
## PA1 PA2
## SS loadings 3.73 2.85
## Proportion Var 0.41 0.32
## Cumulative Var 0.41 0.73
## Proportion Explained 0.57 0.43
## Cumulative Proportion 0.57 1.00
##
## Mean item complexity = 1.8
## Test of the hypothesis that 2 factors are sufficient.
##
## The degrees of freedom for the null model are 36 and the objective function was 7.43 with Chi Square of 4533.59
## The degrees of freedom for the model are 19 and the objective function was 0.4
##
## The root mean square of the residuals (RMSR) is 0.03
## The df corrected root mean square of the residuals is 0.03
##
## The harmonic number of observations is 615 with the empirical chi square 27.79 with prob < 0.087
## The total number of observations was 615 with Likelihood Chi Square = 242.74 with prob < 0.000000000000000000000000000000000000000091
##
## Tucker Lewis Index of factoring reliability = 0.906
## RMSEA index = 0.139 and the 90 % confidence intervals are 0.123 0.154
## BIC = 120.73
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## PA1 PA2
## Correlation of (regression) scores with factors 0.97 0.96
## Multiple R square of scores with factors 0.94 0.93
## Minimum correlation of possible factor scores 0.89 0.86
# Note that there are several estimation methods that can be
# used to extract factors, only one of which I demonstrate
# here. The following is taken from the documentation of the
# fa function: Factoring method fm='minres' will do a minimum
# residual as will fm='uls'. Both of these use a first
# derivative. fm='ols' differs very slightly from 'minres' in
# that it minimizes the entire residual matrix using an OLS
# procedure but uses the empirical first derivative. This
# will be slower. fm='wls' will do a weighted least squares
# (WLS) solution, fm='gls' does a generalized weighted least
# squares (GLS), fm='pa' will do the principal factor
# solution, fm='ml' will do a maximum likelihood factor
# analysis. fm='minchi' will minimize the sample size
# weighted chi square when treating pairwise correlations
# with different number of subjects per pair. fm ='minrank'
# will do a minimum rank factor analysis. 'old.min' will do
# minimal residual the way it was done prior to April, 2017.
PA1 and PA2 indicate the principal axes, or factors. The numbers in each column represent the loading of each item (row) with each factor (column).
Orthogonal Rotation Using Varimax
Even if this is the most reasonable fit for our data, often, unrotated solutions are very difficult to interpret. Rotation usually helps to implement simple structure, where items load highly (.5 or above) with only one factor and fairly low (.2 or lower) with all other factors. This makes it so that you have a better sense of what your latent constructs represent. In this case, the below code will demonstrate how to fit an orthogonal solution, which means that latent factors are not allowed to correlate. Note that this is the stage where you would be deciding whether items are poor items or not (cross-loadings, where an item loads .4 or above with more than one factor is usually considered poor, or an item that does not load highly with any factor (below .4 or .5) are also generally considered poor (Tabachnick and Fidell, 2011). In this case, you would remove the item and redo the factor analysis from the extraction phase.
The type of rotation demonstrated below is an orthogonal rotation. This makes it so that the latent factors are not allowed to correlate (the correlations are fixed at zero). There are many types of orthogonal rotations, varimax is just one of many. You will want to test a few different types of rotations to see which makes the most intepretable solution (with the simplest structure possible) for your data.
factor.2.orthog <- fa(efamat, nfactors = 2, n.obs = 615, rotate = "varimax",
fm = "pa")
# 2 factor orthogonal rotation using varimax
factor.2.orthog #print results
## Factor Analysis using method = pa
## Call: fa(r = efamat, nfactors = 2, n.obs = 615, rotate = "varimax",
## fm = "pa")
## Standardized loadings (pattern matrix) based upon correlation matrix
## PA1 PA2 h2 u2 com
## i1 0.05 0.85 0.72 0.28 1
## i2 0.10 0.88 0.79 0.21 1
## i3 0.08 0.88 0.79 0.21 1
## i4 0.08 0.92 0.86 0.14 1
## i5 0.83 0.04 0.69 0.31 1
## i6 0.88 0.04 0.77 0.23 1
## i7 0.65 0.02 0.42 0.58 1
## i8 0.92 0.00 0.85 0.15 1
## i9 0.83 0.07 0.69 0.31 1
##
## PA1 PA2
## SS loadings 3.44 3.14
## Proportion Var 0.38 0.35
## Cumulative Var 0.38 0.73
## Proportion Explained 0.52 0.48
## Cumulative Proportion 0.52 1.00
##
## Mean item complexity = 1
## Test of the hypothesis that 2 factors are sufficient.
##
## The degrees of freedom for the null model are 36 and the objective function was 7.43 with Chi Square of 4533.59
## The degrees of freedom for the model are 19 and the objective function was 0.4
##
## The root mean square of the residuals (RMSR) is 0.03
## The df corrected root mean square of the residuals is 0.03
##
## The harmonic number of observations is 615 with the empirical chi square 27.79 with prob < 0.087
## The total number of observations was 615 with Likelihood Chi Square = 242.74 with prob < 0.000000000000000000000000000000000000000091
##
## Tucker Lewis Index of factoring reliability = 0.906
## RMSEA index = 0.139 and the 90 % confidence intervals are 0.123 0.154
## BIC = 120.73
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## PA1 PA2
## Correlation of (regression) scores with factors 0.97 0.97
## Multiple R square of scores with factors 0.93 0.94
## Minimum correlation of possible factor scores 0.87 0.88
# arguments for rotate are: 'none', 'varimax', 'quartimax',
# 'bentlerT', 'equamax', 'varimin', 'geominT' and 'bifactor'
# are orthogonal rotations. 'Promax', 'promax', 'oblimin',
# 'simplimax', 'bentlerQ, 'geominQ' and 'biquartimin' and
# 'cluster' are possible oblique transformations of the
# solution. The default is to do a oblimin transformation.
Oblique Rotation Using Direct Oblimin
A second class of rotation is referred to as “oblique.” This type of rotation allows latent factors to correlate.
factor.2.oblique <- fa(efamat, nfactors = 2, n.obs = 615, rotate = "oblimin",
fm = "pa")
# 2 factor oblique rotation using direct oblimin rotation
factor.2.oblique #print results
## Factor Analysis using method = pa
## Call: fa(r = efamat, nfactors = 2, n.obs = 615, rotate = "oblimin",
## fm = "pa")
## Standardized loadings (pattern matrix) based upon correlation matrix
## PA1 PA2 h2 u2 com
## i1 -0.03 0.85 0.72 0.28 1
## i2 0.03 0.88 0.79 0.21 1
## i3 0.01 0.89 0.79 0.21 1
## i4 -0.01 0.93 0.86 0.14 1
## i5 0.83 0.01 0.69 0.31 1
## i6 0.88 0.01 0.77 0.23 1
## i7 0.65 -0.01 0.42 0.58 1
## i8 0.92 -0.03 0.85 0.15 1
## i9 0.83 0.03 0.69 0.31 1
##
## PA1 PA2
## SS loadings 3.42 3.15
## Proportion Var 0.38 0.35
## Cumulative Var 0.38 0.73
## Proportion Explained 0.52 0.48
## Cumulative Proportion 0.52 1.00
##
## With factor correlations of
## PA1 PA2
## PA1 1.00 0.13
## PA2 0.13 1.00
##
## Mean item complexity = 1
## Test of the hypothesis that 2 factors are sufficient.
##
## The degrees of freedom for the null model are 36 and the objective function was 7.43 with Chi Square of 4533.59
## The degrees of freedom for the model are 19 and the objective function was 0.4
##
## The root mean square of the residuals (RMSR) is 0.03
## The df corrected root mean square of the residuals is 0.03
##
## The harmonic number of observations is 615 with the empirical chi square 27.79 with prob < 0.087
## The total number of observations was 615 with Likelihood Chi Square = 242.74 with prob < 0.000000000000000000000000000000000000000091
##
## Tucker Lewis Index of factoring reliability = 0.906
## RMSEA index = 0.139 and the 90 % confidence intervals are 0.123 0.154
## BIC = 120.73
## Fit based upon off diagonal values = 1
## Measures of factor score adequacy
## PA1 PA2
## Correlation of (regression) scores with factors 0.97 0.97
## Multiple R square of scores with factors 0.93 0.94
## Minimum correlation of possible factor scores 0.87 0.88
Ian Ruginski
Postdoctoral Fellow
My research interests include spatial cognition, navigation, data visualization, and human-computer interaction.